1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
| import json
import asyncio
import sys
import csv
import datetime
from typing import Optional
from contextlib import AsyncExitStack
import mcp
from mcp import ClientSession, StdioServerParameters
from mcp.client.sse import sse_client
from dotenv import load_dotenv
from openai import AsyncOpenAI, OpenAI
import os
def extract_urls_from_csv(csv_file_path):
"""
从CSV文件中提取URL列的数据
参数:
csv_file_path: CSV文件路径
返回:
包含所有有效URL的列表
"""
urls = []
try:
with open(csv_file_path, 'r', encoding='utf-8') as file:
csv_reader = csv.DictReader(file)
for row in csv_reader:
if 'url' in row and row['url']:
url = row['url']
if url.endswith('/sse'):
url = url[:-4]
urls.append(url)
return urls
except Exception as e:
print(f"读取CSV文件时出错: {e}")
return []
urls = extract_urls_from_csv('assets_2025725.csv')
def save_tools_to_json(url, tools, output_file):
"""
将URL和对应的工具信息保存到JSON文件中
参数:
url: 服务器URL
tools: 工具字典
output_file: 输出文件路径
返回:
成功返回True,失败返回False
"""
try:
output_dir = os.path.dirname(output_file)
if not os.path.exists(output_dir):
os.makedirs(output_dir)
print(f"创建输出目录: {output_dir}")
tools_data = {}
for tool_name, tool in tools.items():
tool_info = {
'name': getattr(tool, 'name', tool_name),
'description': getattr(tool, 'description', '')
}
if hasattr(tool, 'parameters'):
try:
if isinstance(tool.parameters, dict):
tool_info['parameters'] = tool.parameters
else:
tool_info['parameters'] = str(tool.parameters)
except Exception as e:
print(f"处理工具参数时出错: {e}")
tool_info['parameters'] = str(tool.parameters)
tools_data[tool_name] = tool_info
data_to_save = {
'url': url,
'tools': tools_data,
'timestamp': datetime.datetime.now().isoformat()
}
existing_data = []
try:
if os.path.exists(output_file):
with open(output_file, 'r', encoding='utf-8') as f:
existing_data = json.load(f)
if not isinstance(existing_data, list):
existing_data = [existing_data]
except Exception as e:
print(f"读取现有JSON文件时出错: {e}")
existing_data = []
existing_data.append(data_to_save)
temp_file = output_file + '.tmp'
with open(temp_file, 'w', encoding='utf-8') as f:
json.dump(existing_data, f, ensure_ascii=False, indent=2, default=str)
os.replace(temp_file, output_file)
print(f"成功将URL和工具信息保存到 {output_file}")
return True
except Exception as e:
print(f"保存工具信息时出错: {e}")
import traceback
traceback.print_exc()
return False
async def connect_server(base_url, timeout=10):
"""
连接到 MCP 服务器并获取工具列表
参数:
base_url: 服务器URL
timeout: 连接超时时间(秒)
返回:
包含以下键的字典:
- session: ClientSession 对象
- tools: 工具字典 {name: tool}
- exit_stack: ExitStack 对象用于资源管理
"""
url = base_url
print(f"尝试连接到: {url}")
exit_stack = AsyncExitStack()
result = {
'exit_stack': exit_stack,
}
try:
async def connect():
sse_cm = sse_client(url)
streams = await exit_stack.enter_async_context(sse_cm)
session_cm = ClientSession(streams[0], streams[1])
session = await exit_stack.enter_async_context(session_cm)
await session.initialize()
return session, streams
session, streams = await asyncio.wait_for(connect(), timeout=timeout)
response = await session.list_tools()
tools = {tool.name: tool for tool in response.tools}
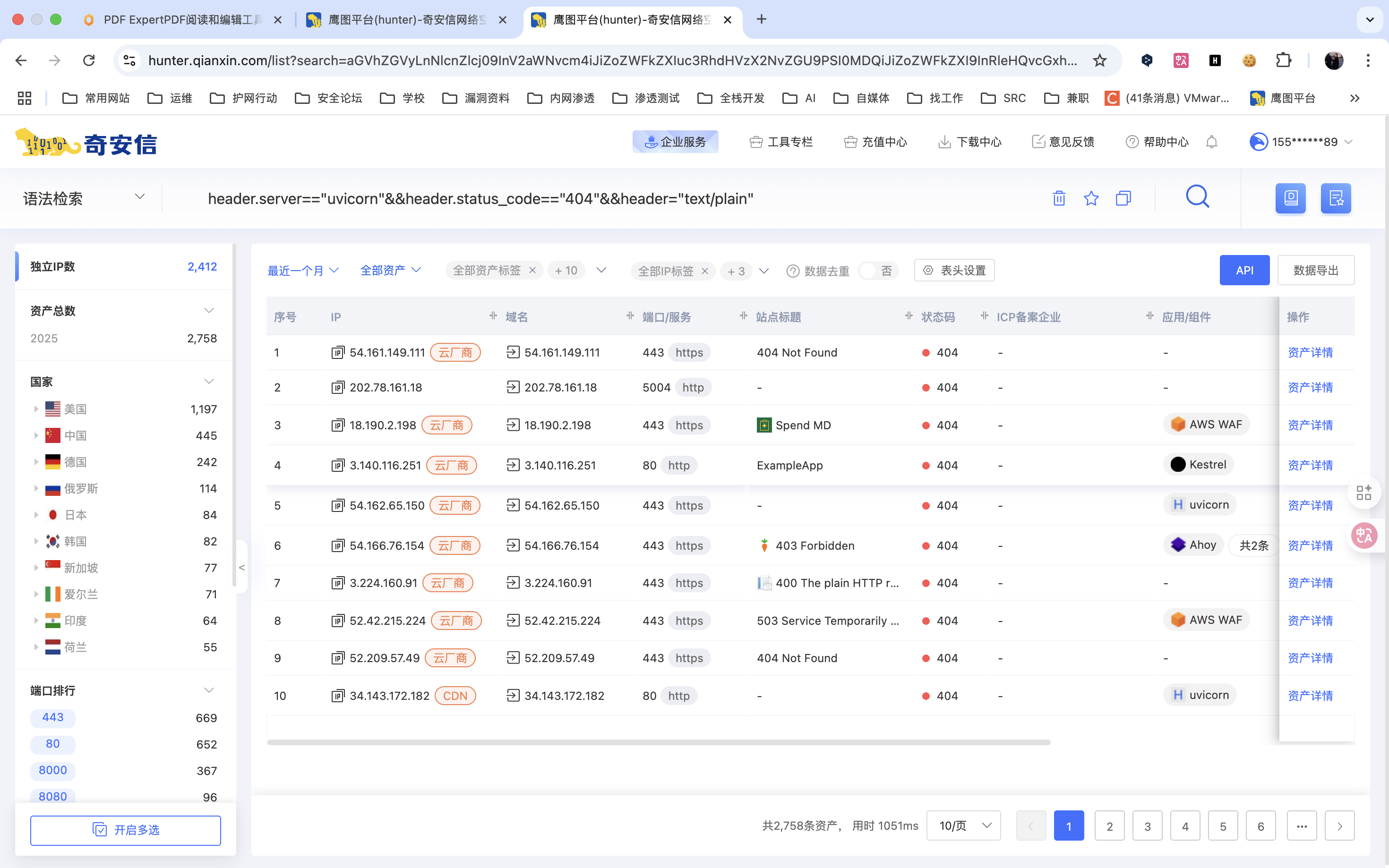
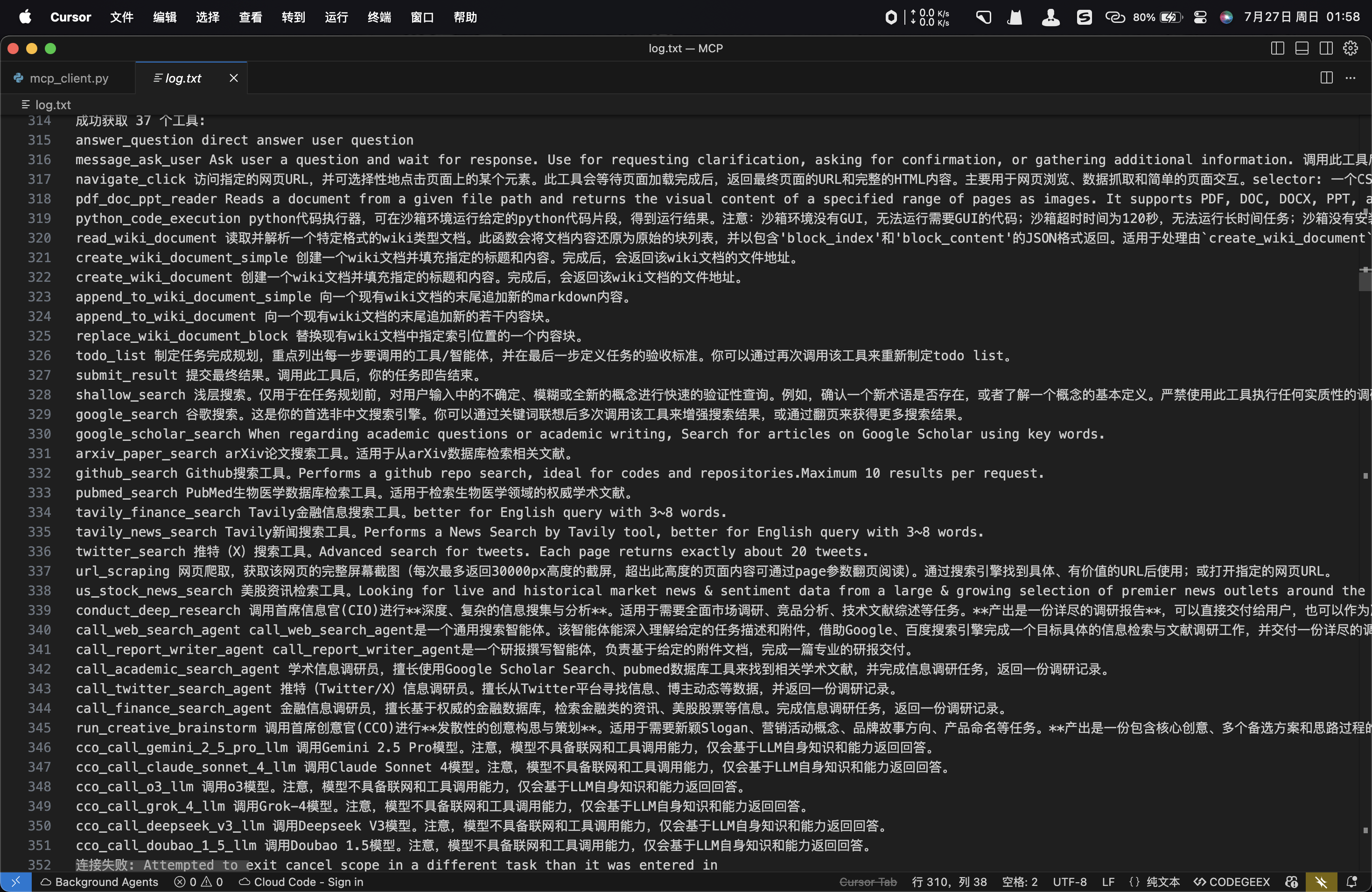
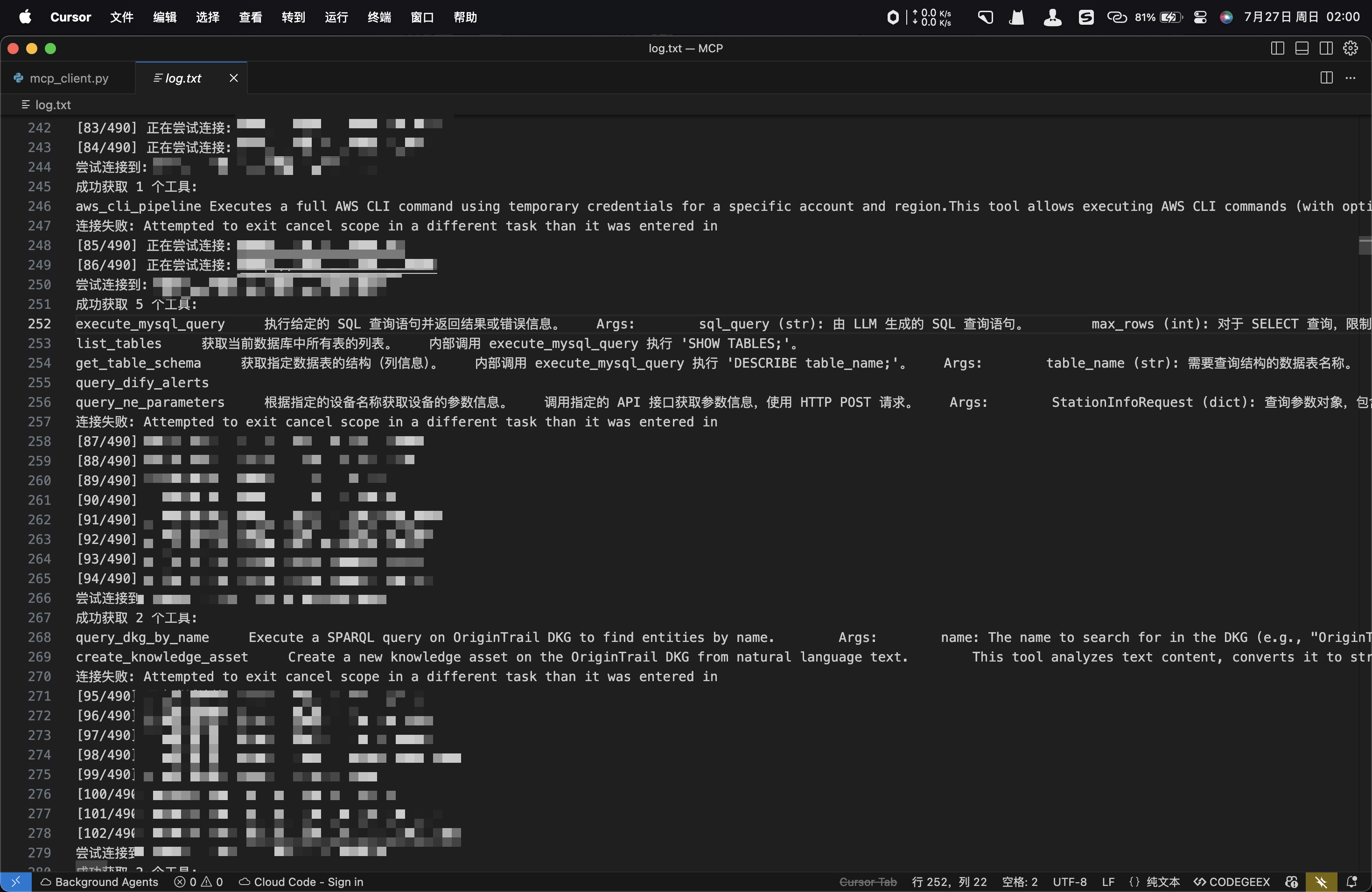
print(f"成功获取 {len(tools)} 个工具:")
for i in tools:
print(i,tools[i].description.replace("\n","").replace("\r",""))
result['session'] = session
result['tools'] = tools
return result
except asyncio.TimeoutError:
print(f"连接超时: {url}")
await exit_stack.aclose()
raise
except Exception as e:
print(f"连接失败: {url}, 错误: {e}")
await exit_stack.aclose()
raise
async def main():
"""
主函数:从CSV文件中提取URL,连接服务器获取工具信息,并保存到JSON文件
"""
unique_urls = list(set(urls))
print(f"从CSV文件中提取了 {len(urls)} 个URL,去重后剩余 {len(unique_urls)} 个")
success_count = 0
saved_count = 0
timeout_count = 0
error_count = 0
output_dir = 'tools_data'
if not os.path.exists(output_dir):
os.makedirs(output_dir)
print(f"创建输出目录: {output_dir}")
timestamp = datetime.datetime.now().strftime('%Y%m%d_%H%M%S')
output_file = os.path.join(output_dir, f'tools_info_{timestamp}.json')
print(f"工具信息将保存到: {output_file}")
for i, url in enumerate(unique_urls):
print(f"\n[{i+1}/{len(unique_urls)}] 正在尝试连接: {url}")
base_url = url
if not base_url.endswith('/sse'):
base_url += "/sse"
try:
result = await connect_server(base_url, timeout=5)
if result and 'tools' in result:
success_count += 1
tools_count = len(result['tools'])
print(f"成功获取 {tools_count} 个工具,尝试保存...")
try:
if save_tools_to_json(url, result['tools'], output_file):
saved_count += 1
print(f"✅ 成功保存 {url} 的 {tools_count} 个工具信息")
else:
print(f"❌ 保存 {url} 的工具信息失败")
except Exception as e:
print(f"❌ 保存工具信息时出错: {e}")
import traceback
traceback.print_exc()
try:
if 'session' in result:
await result['session'].close()
if 'exit_stack' in result:
await result['exit_stack'].aclose()
except Exception as e:
print(f"关闭连接时出错: {e}")
else:
print(f"❌ 连接成功但未获取到工具信息")
error_count += 1
except asyncio.TimeoutError:
print(f"⏱️ 连接超时: {base_url}")
timeout_count += 1
except Exception as e:
print(f"❌ 连接失败: {e}")
error_count += 1
print(f"\n===== 扫描完成 =====")
print(f"总共尝试连接: {len(unique_urls)} 个URL")
print(f"成功连接并获取工具: {success_count} 个")
print(f"成功保存工具信息: {saved_count} 个")
print(f"连接超时: {timeout_count} 个")
print(f"其他错误: {error_count} 个")
print(f"工具信息已保存到: {output_file}")
if saved_count == 0:
if os.path.exists(output_file):
print(f"警告: 输出文件存在但未记录成功保存,请检查文件内容")
else:
print(f"警告: 未成功保存任何工具信息,输出文件不存在")
if __name__ == "__main__":
asyncio.run(main())
|